A. Python ミニ・チュートリアル¶
このミニ・チュートリアルは,本文の3章・4章で触れた Python 仕様をもう少し詳しく説明するものです.2章までの理解を前提としています.Python の全機能をカバーするものではありません.
A.1. 文の実行¶
A.1.1. 上から 1 行ずつ実行される¶
Python のプログラムは,書かれた順に 1 行ずつ実行されるのが基本です.
C 言語のようにセミコロン ; をつけて文が終わることを示す必要はありません.その代わり,勝手なところに改行を入れることはできません.
2章で見た通り,インデント (字下げ) にも意味があるので,行の先頭に勝手に空白を入れてはいけません.
A.1.2. コメント¶
# から行末まではコメント (comment) です.実行されません.複数行にわたるコメントを書くには,""" と """ で挟む方法もあります:
# この行はコメントです
x = 12
y = 456 # 行の途中からコメントにすることもできます
# 複数行のコメントは,すべての行に # をつけるか,
# あるいは """ と """ で囲みます
"""これも
コメントとして扱えます
"""
厳密には,""" で挟まれた部分はコメントではなく「改行を含む長い文字列」です.文字列を評価するだけの文は「何もしない」のと同じことなので,コメントのように扱えるという仕組みです.そのため,# とは違って正しいインデントレベルで書く必要があります:
# この行はコメントです
## 字下げしても構いません.
"""これは
厳密には文字列です.
"""
"""このように勝手に字下げすると
エラーになります
"""
コメントは,コードに対して注記をするという本来の目的のほか,一部のコードを一時的に実行しないようにする目的でもよく使います.コメントアウトする (comment out) といいます.
ただし,せっかく Git で履歴管理をしていて過去のコードはいつでも取り出せるのだから,長いことコメントアウトされたままのコードは,横着せずに消しましょう.
コメントアウトされたコードを元に戻すことは,あまり標準的な用語ではありませんが,アンコメントする (uncomment) ということが多いようです.(コメントインとは言いません.コメントを入れるっぽく聞こえるので)
A.1.3. 行の継続¶
1 行が長くなってしまって途中で改行したくなった場合は,行末に \ を置くと次の行に継続させることができます.ただし,かっこ類 () [] {} の中では自由に改行して構いません.まだ文が終わっていないことが明らかだからです:
# これは「\」が必要です
variable_with_very_very_long_name = \
function_with_very_very_long_name(123, 456, 789)
# こちらは「\」を使わずに改行できます
another_variable = function_with_very_very_long_name(123,
456,
789)
A.2. 変数と演算¶
A.2.1. 算術式¶
式の書き方は他の多くのプログラミング言語と似ているのであまり迷うことはないと思います:
>>> 3 + 2
5
>>> 4 - 8
-4
>>> (2 + 3) * 4
20
>>> 10 / 4
2.5
>>> 10 // 4
2
>>> 10 % 3
1
>>> 10 ** 3
1000
>>> 3.14 * 2 * 2
12.56
/ が実数除算,// が整数除算である点には注意が必要です.
% は剰余,** は累乗です.
演算の優先順位や結合方向も他の多くの言語と同じです:
>>> 6 - 3 - 2
1
>>> 6 + 3 * 2
12
>>> 6 / 3 / 2
1.0
A.2.2. 変数と代入¶
代入文 (assignment statement) を使うと,左辺の変数に右辺の値を割り当てることができます:
>>> pi = 3.14
>>> radius = 5
>>> pi * radius ** 2
78.5
変数の使用をあらかじめ宣言しておく必要はありません.最初に代入される時点で定義されます.
C言語のような累積代入演算子も使えます:
>>> x = 10
>>> x += 2
>>> x
12
>>> x -= 5
>>> x
7
>>> x *= 10
>>> x
70
ただし,C 言語でよく使われる ++ (1を加算) や -- (1を減算)
はありません.代わりに x += 1 や x -= 1 のように書きます.
左辺をカンマで区切って,タプルの内容をバラして代入できることを2章で使いました.右辺にはタプルだけではなく限らず,カンマ区切りの値を与えることもできます:
>>> x, y = (100, 200)
>>> x, y = y, x
>>> (x, y)
(200, 100)
こうやって2つの変数の値を入れ替えることは,C言語だと1行ではできません.
A.2.3. 型と型変換¶
値には,それぞれが属する型があります.
Python で定義されている基本的な型 (プリミティブ型) としては整数 (int) 型,実数 (float) 型,真偽値 (bool) 型などが挙げられます.型は type 関数によって調べることができます:
>>> type(5)
int
>>> type(5.0)
float
>>> type(2e-3)
float
>>> type(True)
bool
>>> type(False)
bool
ただし 2e-3 は \(2^{-3}\) の意味です.
型名を関数のように使うと,つまり,何らかの値を丸かっこで囲んだものの前に型名をつけると,型変換が行われます.もちろん変換が定義されている型の間でしかできません:
>>> float(5)
5.0
>>> int(2.5)
2
>>> bool(1)
True
実数から整数への変換では丸めが生じます.整数や実数から真偽値への変換は,0 が False に,0 以外が True
になります.
A.3. 関数¶
A.3.1. 関数の定義¶
一連の処理に名前をつけて呼び出せると便利です.それを関数 (function) と呼びます.2章までに出てきた例としては
print や pygame.init などがあります.同じようなものを自分で定義することができます:
def 関数名(引数1, 引数2, 引数3):
関数本体の処理
...
return 返り値
のように書くのが典型的な定義のしかたです.
def の行の最後にコロン :
が必要です.その次の行から関数の中身を書きますが,インデントが必要なことに注意してください.
引数はいくつあっても構いません.引数を取らないときは def 関数名():
のようにかっこの中を空にします.
return 文が実行されると,呼び出し元に戻ります.呼び出し元が式の一部だったときは,そこの値として「返り値」が使われます.値を返さないときは
return だけ書きます.関数本体の最後の行が return だけのときは省略しても構いません (返り値なしで勝手に呼び出し元に戻ります).
A.3.3. デフォルト引数とキーワード引数¶
関数定義の際,引数が省略されたときに使われるデフォルト値を指定しておくことができます:
def func_abc(a, b=20, c=10):
return (a + b) * c
のように定義された関数 func_abc は,以下のように呼び出せます:
>>> func_abc(2, 3, 5)
25
>>> func_abc(2, 3) # c を省略
50
>>> func_abc(2) # b, c を省略
220
関数定義の際,引数の順番は,デフォルト値のないものが先に,デフォルト値つきのものが後になるようにしなくてはなりません.
関数呼び出しの際,引数を出現順ではなく名前付きで呼び出す方法をキーワード引数といいます.さっきの関数 func_abc は以下のように呼び出すこともできます:
>>> func_abc(2, b=3, c=10) # a は位置指定, b, c をキーワード指定
50
>>> func_abc(2, c=10, b=3) # キーワード引数は順序は自由
50
>>> func_abc(2, c=3) # b だけ省略
66
>>> func_abc(c=3, a=2)
66
>>> func_abc(c=3, 2) # 位置指定はキーワード指定の後に置けない
File "<stdin>", line 1
func_abc(c=3, 2)
^
SyntaxError: positional argument follows keyword argument
なお,関数定義時に,一部の引数を位置指定限定にしたりキーワード指定限定にしたりすることもできます.
A.4. 制御文¶
if 文や while 文を使うことで,プログラム内の文の実行順序を制御できることは2章でも見てきた通りです.同様のものでよく使うものを見ていきます.
A.4.1. if 文と仲間たち¶
条件が成立したときと成立しなかったで実行する内容を変化させることができます:
if 条件:
条件成立時に実行する部分
else:
条件不成立時に実行する部分
「…時に実行する部分」のところは複数行の文があっても構いません.
else 以降は省略できて,2章で使った if 文では省略されていました.
C言語などに慣れている人は,インデントが常に必要なことと,条件や else の後にコロン : が必要なことに注意してください.
else のところにさらに条件を入れて,連鎖させることもできます.
if 条件1:
条件1成立時に実行する部分
elif 条件2:
条件1が不成立で条件2が成立した時に実行する部分
elif 条件3:
条件1も条件2も不成立で条件3が成立した時に実行する部分
else:
条件1も条件2も条件3も不成立のときに実行する部分
「else if」の略で elif です.elif の部分はいくつあっても構いません.最後の else はなくても構いません.
A.4.2. 条件の書き方¶
if や elif の条件部には真偽値型の値を入れます.True なら条件成立,
False なら不成立です.
真偽値型の値を作る演算としては,等号や不等号などの関係演算子がおなじみだと思います.C言語と同じく,関係演算子の等号とその否定には == と
!= を,不等号には >, >=, <, <= を使います.特に,代入演算子 = と等号演算子 == が別であることに注意してください.
真偽値は「かつ」「または」「否定」などの論理演算で組み合わせることができます.それぞれ and, or, not を使います.C 言語に慣れている人は,&&, ||, ! ではないことに注意してください:
>>> a = 10 # 代入 (等号ではない)
>>> a == 10 # a は 10 と等しいか?
True
>>> 2 <= a and a < 8 # a は 2 以上 8 未満か?
False
>>> not (2 <= a and a < 8) # 上の条件の否定
True
>>> (not 2 > a) or (not a >= 8) # ド・モルガン則により上の条件と等価
True
A.4.3. while文・for 文¶
繰り返し (ループ) を行うものとして,2章で while 文を使いました:
while 条件:
ループの本体
for 文も繰り返しを行うもので,例えば以下のような書き方をします:
for x in (0, 1, 2, 3, 4):
print(x + 3)
この例を実行すると以下のように表示されます:
3
4
5
6
7
この場合,in の後ろにあるタプルの要素が1つずつ x に代入され,それぞれの x に対して print(x + 3) の部分が実行されます.
in の後ろのところに置けるのはタプルだけではなく,同様に何らかのデータが直列に並んだもの (Python ではシーケンスと総称します) も置くことができます.次節で扱う「リスト」もシーケンスの一種です.
上の例の (0, 1, 2, 3, 4) のように直接書く以外の方法でシーケンスを作る方法はたくさんありますが,代表的な書き方だけを挙げておきます.
range という関数を使うものです:
for x in range(5):
print(x + 3)
ここで,range(5) は 0 から始まり 5 より小さい整数のシーケンスを返します.つまり (0, 1, 2, 3, 4) を指定したのと同じです.5 が含まれないことに注意してください.C 言語に慣れている人は for (x = 0; x <
5; x++) ... に相当するものだと覚えておくとよいでしょう.
A.4.4. break文・continue文¶
while 文や for 文のような繰り返し文の途中で,ループから抜け出すには,
2章でも見た通り break 文を使います.
continue 文はこれと似ていますが,ループから抜けるのではなく,繰り返しの現在の回をスキップして,次の回に進みます:
for x in (1, 2, 3, 4):
if x == 3:
continue
print(x)
これを実行すると以下のように表示されます:
1
2
4
A.4.5. グローバル変数とローカル変数¶
関数の中で変数を定義すると,その関数内からしか見えないローカル変数になります.それに対してファイル全体から見えるものをグローバル変数と呼びます.
C言語等に慣れている人は,while 文や for 文などの中でしか見えない「ブロックローカル変数」が Python には無いことに注意してください:
def func():
for item in (10, 20, 30):
print(item)
for item in (99, 98, 97):
print(item)
のように書いたとき,1-2行目の item と 3-4行目の item は同じものです.そのため,ここでうっかりスペルミスをして:
def func():
for item in (10, 20, 30):
print(item)
for irem in (99, 98, 97):
print(item)
などと書いてしまうと,エラーにならずに謎の挙動で悩むことになりがちなので注意が必要です:
>>> func()
10
20
30
30
30
30
A.5. リスト (list型)¶
for 文で処理する対象として,データが直列に並んだシーケンスなるものを取ることができるという話をしました.
Python では,シーケンスとして扱えるデータ構造は多数あるのですが,その中で最重要なものがリスト (list) です:
>>> x = [0, 1, 2, 3, 4]
このように書くと,0 から 4 までの整数が並んだ 5 要素のリストが変数
x に割り当てられます.タプルと似ていますが,丸かっこではなく角かっこを使います.
リストの特徴は,長さを変更したり,要素を書き換えたりすることができる点です.実はタプルはこれらが許されていません.一度作ったらそのまま変更できない (immutable) のがタプル,変更できる (mutable) のがリストです.
リストを操作する手段のうち基本的なものだけ説明します.他にもたくさんありますので公式マニュアル等を参照してください.
A.5.1. シーケンスの操作¶
まず,リストやタプルなどのシーケンスに共通する操作を挙げます.
A.5.1.1. インデックス¶
角かっこで囲んだインデックス (添字) をリストの後ろに書くことで,リストの要素にアクセスできます.インデックスは 0 から始まります:
>>> x = [10, 20, 30, 40, 50]
>>> x[0]
10
>>> x[2]
20
インデックスとして負数を指定すると,最後尾から数えた位置を指定できます:
>>> x[-1]
50
>>> x[-2]
40
A.5.1.2. スライス¶
単一のインデックスで要素を指定する代わりに,x[begin:end] という形式で,インデックスが begin から end 未満の部分リストにアクセスできます.インデックスが end の要素を含まないことに注意してください.このように指定される部分リストをスライス (slice) と呼びます:
>>> x[2:4]
[30, 40]
>>> x[1:5]
[20, 30, 40, 50]
begin あるいは end のところを省略すると,それぞれ「最初からインデックス end 未満」,「インデックス begin から最後まで」が指定されます:
>>> x[2:]
[30, 40, 50]
>>> x[:2]
[10, 20]
A.5.1.3. 基本演算¶
演算子 + によってシーケンスどうしを結合したものを,
* によってシーケンスを複数回繰り返したものを表すことができます:
>>> x = [10, 20, 30]
>>> y = x + [40, 50]
>>> y
[10, 20, 30, 40, 50]
>>> z = x * 3
>>> z
[10, 20, 30, 10, 20, 30, 10, 20, 30]
この例で,x 自体は変化していないことに注意してください.演算結果が新しいリストとして返されているだけです.(そうでないとタプルのような変更不能なものに適用できません)
シーケンス長は関数 len で得ることができます:
>>> len([10, 20, 30])
3
ある値がシーケンスに含まれるか否かを調べるには演算子 in, not
in が使えます.ただし,シーケンスの先頭から1つずつチェックしていくので,長いシーケンスの後ろの方に目当ての要素がある場合は遅いです:
>>> x = [10, 20, 30, 40, 50]
>>> 30 in x
True
>>> 30 not in x
False
>>> 35 in x
False
A.5.2. リストの作成¶
A.5.2.1. range¶
for 文で使う連番を作るのに使った range 関数を,もう少し詳しく見ていきます.
まず,range は実はリストやタプルを返す関数ではありません.では何なのかというと range オブジェクトなるものなのですが,その説明はちょっと難しいのでパスします.とりあえず,リストではないがリストに変換できるものだと理解しておいてください.
そのため,for 文の in の後などには直接置いてよいのですが,リストとして変数に代入したりするためには型変換が必要です:
>>> x = range(5)
>>> x
range(0, 5)
>>> x = list(range(5))
>>> x
[0, 1, 2, 3, 4]
上の例のように range に引数を 1 個渡すと,0 から始まる連番を作れるのでした.最初の値を変えたいときは引数を 2 個渡します:
>>> list(range(2, 6))
[2, 3, 4, 5]
第1引数が最初の値, 第2引数が「最後」の値で,ただし最後の値は結果に含まれません.スライスと同じルールです.
第3引数を使うと,増分を指定することができます.以下のように書くと,2 から始まって 3 ずつ増え,10 に至る前に終わる数列が得られます:
>>> list(range(2, 10, 3))
[2, 5, 8]
これを利用すると,他の言語の for 文でよく使う書き方はだいたいできることになります.
for (x = 2; x < 10; x += 3) {
printf("%d\n", x); /* 整数 x の値と改行文字を表示 */
}
for (x = 10; x > 0; x -= 1) {
printf("%d\n", x);
}
for x in range(2, 10, 3):
print(x)
for x in range(10, 0, -1):
print(x)
A.5.2.2. リスト内包記法¶
もう1つ,リストを作る便利な記法を紹介しておきます.リスト内包記法 (list comprehension) というちょっととっつきにくい名前で呼ばれます:
>>> x = [1, 2, 15, 30]
>>> x_doubled = [2 * a for a in x]
>>> x_doubled
[2, 4, 30, 60]
>>> even_values_doubled = [2 * a for a in x if a % 2 == 0]
>>> even_values_doubled
[4, 60]
>>> powers_of_two = [2 ** n for n in range(5)]
>>> powers_of_two
[1, 2, 4, 8, 16]
集合を表す数学記法と対比するとわかりやすいと思います. \(\mid\) を for と,\(\in\) を in と読むわけです.
ただし,数学でいう集合の要素には順番がありませんが,リストには順番があることに注意してください.うまく使うと複雑なリストを簡潔に表現することができます.
A.5.3. リスト要素の変更¶
インデックス指定やスライスを代入文の左辺に置けば,リストのうち指定の要素を変更できます:
>>> x = [10, 20, 30, 40, 50]
>>> x[2] = 12345
>>> x
[10, 20, 12345, 40, 50]
>>> x[2:4] = [-20, -30]
>>> x
[10, 20, -20, -30, 50]
A.5.4. リストの伸縮¶
A.5.4.1. 要素の追加,挿入¶
リストは変更可能なので,長さが変わるような操作も可能です.append
というメソッドで末尾への要素の追加を,insert というメソッドで指定されたインデックスへの要素の挿入を行えます:
>>> x = []
>>> x.append(0)
>>> x.append(10)
>>> x.append(20)
>>> x.append(30)
>>> x
[0, 10, 20, 30]
>>> x.insert(2, 12345)
>>> x
[0, 10, 12345, 20, 30]
A.5.4.2. 要素の削除¶
pop というメソッドは,末尾の要素をリストから削除して,その値を返します:
>>> x = [0, 10, 20, 30, 40, 50]
>>> item = x.pop()
>>> item
50
>>> x
[0, 10, 20, 30, 40]
>>> item = x.pop()
>>> item
40
>>> x
[0, 10, 20, 30]
pop メソッドに引数としてインデックスを与えると,指定された要素を削除してその値を返します:
>>> item = x.pop(2)
>>> item
20
>>> x
[0, 10, 30]
削除された値を返す必要がないときは del 文が使えます.単一インデックスによる指定だけでなく,スライスでの指定もできます:
>>> x = [0, 10, 20, 30, 40, 50]
>>> del x[3]
>>> x
[0, 10, 20, 40, 50]
>>> del x[1:4]
>>> x
[0, 50]
>>> del x[:]
>>> x
[]
上の例のように del x[:] とすれば全要素を削除できますが,clear
メソッドを使う方が少し速いです:
>>> x = [10, 20, 30]
>>> x.clear()
>>> x
[]
値を指定して削除するメソッド remove も用意されています.引数と等しい値の要素をリストの先頭から探していき,最初に見つかったものを削除します:
>>> x = [0, 10, 20, 30, 40, 50]
>>> x.remove(30)
>>> x
[0, 10, 20, 40, 50]
A.5.4.3. 要素の追加・削除はできるだけ末尾から行う¶
リストというのは,要素が直列に並んでいるデータ構造です.末尾以外に要素を追加したり末尾以外の要素を削除するのは効率が悪いです.
例えば最初にこういうリストがあったとして:
>>> x = [10, 20, 30, 40]
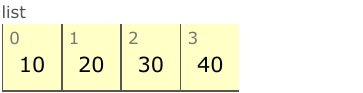
末尾に要素を追加しても,前からあった要素を動かす必要はありませんが:
>>> x.append(50)
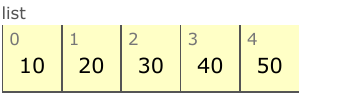
末尾以外に要素を挿入すると,そこより後ろをすべてずらして保存し直す必要があります:
>>> x.insert(0, 99)

ですので,リストを伸縮させるときはできるだけ append か引数なしの
pop を使えるように構造や計算手順を考えるのが望ましいです.
A.6. リストと類似したデータ構造¶
A.6.1. タプル (tuple型)¶
タプル (tuple) もシーケンスの一種であり,リスト同様にインデックスやスライスによるアクセスができ,+ や * による結合や繰り返しができ,len
関数で長さを得ることができます.
しかし,リストとは違って変更不能です.append や
pop のように長さを変えるメソッドは使えませんし,インデックスやスライスを使って要素を変更することもできません:
>>> tup = (10, 20, 30)
>>> tup[0]
10
>>> tup[1] = 123
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
A.6.2. 文字列 (str型)¶
文字列 (string) は "hello, world" や "red" のようにダブルクォートで囲むことで表してきました.実はシングルクォートで 'hello, world' や
'red' のように書いても構いません.
このテキストでは主にダブルクォートを使っていますが,Python が計算結果として返すものは主にシングルクォートで表記されます:
>>> "hello"
'hello'
どちらでも良いのですが,文字列の中に " や ' 自体を入れたいときは使い分けると便利です:
>>> print("what's new")
what's new
>>> print('1" is equal to 25.4 mm')
1" is equal to 25.4 mm
囲むのに使ったクォート文字と同じ文字をどうしても文字列中に入れたいときは,\ をその文字の前につけます.\ はこのように,文字列の中に含めたいのだけれども直接書くことができないものを表すのに使われます.このような使い方をエスケープといいます.他の使い方としては,\n で改行文字を表したり,\t でタブ文字を表したり,\\ と書いて \ 自体を表したり等が挙げられます:
>>> print('1h 23\' 45"')
1h 23' 45"
>>> print("hello\nworld")
hello
world
>>> print("C:\\Windows\\System32")
C:\Windows\System32
文字列の型名は str です.例えば整数や実数から型変換すると,標準的な書式で表した文字列が得られます.書式を調整したい場合は後述する
format メソッドを使う必要があるでしょう:
>>> str(123)
'123'
>>> str(2 * 4 * 3.14)
'25.12'
>>> str(1e3)
'1000.0'
A.6.2.1. シーケンスとしての文字列¶
文字列も変更不能なシーケンスの一種です.インデックスやスライスによるアクセス,len や + や * の適用,for 文やリスト内包記法での使用など,変更を伴わない操作はリストやタプルと同様にできます:
>>> s = "auto" + "maton"
>>> s
'automaton'
>>> len(s)
9
>>> s[2]
't'
>>> s[2:8]
'tomato'
>>> [c * 2 for c in "hello"]
['hh', 'ee', 'll', 'll', 'oo']
A.6.2.2. 文字列型のメソッド¶
文字列型には特有のメソッドがたくさん用意されています.
もちろんすべては紹介し切れないので,いくつかピックアップして例示します:
>>> "Computer Seminar I".split()
['Computer', 'Seminar', 'I']
>>> ", ".join(["abc", "def", "ghi"])
'abc, def, ghi'
>>> "2021-10-01".replace("-", "/")
'2021/10/01'
>>> "{} errors found in {}".format(10, "hello_pygame.py")
'10 errors found in hello_pygame.py'
文字列は変更不能なので,どのメソッドでも元の文字列は決して変更されないことに注意してください.例えば,replace を例に取ると:
>>> old_string = "2021-10-01"
>>> new_string = old_string.replace("-", "/")
>>> new_string
'2021/10/01'
>>> old_string
'2021-10-01'
のように,元の文字列が変化するわけではありません.あくまで置換結果を新しい文字列として返すだけです.
A.6.2.3. format メソッドの書式¶
format メソッドは少し説明が必要だと思います.上の例では,引数として渡した整数 10 と文字列 "hello_pygame.py" を,元の文字列内の
{} の部分に順に埋め込んだものを返しています.
{} の部分では,{0} や {1} のように番号を書くことで何番目の引数を埋め込むかを指定できます.埋め込まれるときの書式を指定する必要がある場合は,{} の中で : に続けて書式指示を書きます.書式の指定方法も多岐にわたるので,いくつか例を挙げるに留めます:
>>> "{1} {2}, {0}".format(2021, "October", 1)
'October 1, 2021'
>>> "{:5}".format(123) # 5文字に満たなければ空白づめ
' 123'
>>> "{:05}".format(123) # 5文字に満たなければ0づめ
'00123'
>>> "{:.4f}".format(3.141592) # 小数点以下4桁に丸め
'3.1416'
>>> "{:10.4f}".format(3.141592) # 丸め + 空白づめ
' 3.1416'
>>> "{0} {0:5} {0:05}".format(123) # 引数指定 + 書式
'123 123 00123'
A.6.3. 辞書 (dict型)¶
リスト,タプル,文字列はシーケンスなので,要素には順序があり,整数インデックスで要素を指定することができました.
整数ではなく,例えば文字列などを「インデックス」の代わりに使えると便利な場合があります.Python ではこれを辞書 (dictionary) と呼びます:
>>> score = {"Alice": 80, "Bob": 80, "Charlie": 80}
>>> score["Alice"] = 90
>>> score["Bob"] -= 10
>>> score["Alice"]
90
>>> score["Bob"]
70
>>> score["Charlie"]
80
インデックスの代わりに使われるもの (この例では "Alice" など) はキー (key) と呼ばれます.キーと値の組を保持して,キーによる検索が可能なデータ構造が辞書です.同様のものを,他のプログラミング言語では連想配列,ハッシュ,マップなどと呼んだりもします.
キーになれるのは文字列に限りませんが,変更不能なものでなくてはなりません.よってリストはキーになれませんが,タプルはキーになれます.
リストの定義は角かっこ,タプルは丸かっこでしたが,辞書を定義するには1
行目のように波かっこを使います.キーと値をコロン : で組にしたものを,カンマ区切りで並べます.ただし辞書の値にアクセスするときはリストやタプルと同様に角かっこを使います (波かっこではありません).
A.6.3.1. 追加と削除¶
上の例からわかる通り,辞書は変更可能です.新しいキーも追加可能ですし,削除することもできます:
>>> score["Dave"] = 95
>>> del score["Charlie"]
>>> score
{'Alice': 90, 'Bob': 70, 'Dave': 95}
score["Dave"] = 95 のように存在しないキーを新しく作ることは可能ですが,存在しないキーに対する値を読み出そうとするとエラーになります:
>>> score["Charlie"]
KeyError: 'Charlie'
A.6.3.2. キーの存在判定¶
そのため,あるキーが存在しているかどうかチェックしたくなることがよくあります.演算子 in や not in を使うとチェックできます:
>>> "Alice" in score
True
>>> "Alice" not in score
False
>>> "Charlie" in score
False
例えば以下のような使い方が典型的です:
def increment_value(dic, key, delta):
if key not in dic:
dic[key] = 0
dic[key] += delta
increment_value(score, "Charlie", 10)
キーによる辞書の検索や,in や not in による存在判定にかかる時間は,辞書に含まれる要素数に依存しないという特徴があります.この点は,リストに対する in や not in による存在判定と対照的です.
A.6.3.3. リストへの変換¶
辞書に含まれるものすべてに対して何らかの処理をしたいこともよくあります.辞書をリストに型変換するとキーのリストが得られるので,for 文などで処理するとよいです:
>>> list(score)
['Alice', 'Bob', 'Charlie']
A.6.3.4. pygame での利用例¶
辞書の pygame での利用例を見てみましょう.2章で pygame.Color への引数として渡すことのできる色名を知るために以下のページを見てもらいました.
今このページを見ると,何が行われているのか把握できるのではないかと思います.THECOLORS という辞書が定義されていて,例えば
"aliceblue" というキーに対して (240, 248, 255, 255) という値が返るようになっています.この 4 つの数値はそれぞれ赤,緑,青,不透明度を 0 から 255 までの整数で表したもので,ディスプレイに色を表示するときに使われます.このような辞書が pygame の内部で使用されていたわけです.
A.7. 複合的なデータ構造¶
この付録では,要素として整数を持つようなシーケンスばかりを扱ってきましたが,実数や文字列のリストも作れますし,それらが混在するものも可能です.さらには,リストやタプルを要素とすることも可能です:
>>> x = [10, 20, 3.14, "abc"]
>>> y = [10, 20, [99, 88, ["a", "b", "c"]], 40, 50]
これらの詳細については,4章の4.4節以降を参照してください.